FaceScrub Results
Identification Rate vs. Distractors Size
| Algorithm | Date Submitted | Set 1 | Set 2 | Set 3 | Data Set Size |
|---|---|---|---|---|---|
| Sogou AIGROUP - SFace | 9/5/2018 | 99.939% | 99.939% | 99.939% | Large |
| SRC-Beijing-FR(Samsung Research Institute China-Beijing) | 8/15/2018 | 99.888% | 99.888% | 99.888% | Large |
| SenseTime PureFace(clean) | 6/13/2018 | 99.801% | 99.801% | 99.801% | Large |
| EI Networks | 8/10/2018 | 99.414% | 99.414% | 99.414% | Large |
| ICARE_FACE_V1 | 9/13/2018 | 99.3198% | 99.3198% | 99.3198% | Large |
| Sogou | 6/12/2018 | 99.2% | 99.2% | 99.2% | Large |
| Uniview Technology | 8/12/2018 | 99.196% | Large | ||
| QINIU ATLAB - FaceX V1 (iBUG cleaned data) | 7/23/2018 | 99.132% | 99.132% | 99.132% | Large |
| Visual Computing-Alibaba-V1(clean) | 8/6/2018 | 99.126% | Large | ||
| TUPUTECH V1 (iBUG cleaned data) | 4/24/2018 | 99.087% | Large | ||
| TUPUTECH v2 | 4/25/2018 | 99.078% | Large | ||
| BingMMLab V1(iBUG cleaned data) | 4/10/2018 | 98.998% | Large | ||
| ATLAB-FACEX (QINIU CLOUD) | 6/23/2018 | 98.61% | 98.61% | 98.61% | Large |
| cyberlink_resnet-v2 | 9/5/2018 | 98.455% | 98.455% | 98.455% | Large |
| CyberLink | 8/30/2018 | 98.448% | 98.448% | 98.448% | Large |
| Orion Star Technology (clean) | 3/21/2018 | 98.355% | Large | ||
| Beijing Faceall Co. & BUPT(iBug cleaned) | 8/8/2018 | 98.093% | 98.093% | 98.093% | Large |
| iBUG_DeepInsight | 2/8/2018 | 98.063% | 98.058% | 98.053% | Large |
| 4paradigm | 8/24/2018 | 97.977% | Large | ||
| 4paradigm | 8/18/2018 | 97.977% | Large | ||
| sophon | 5/15/2018 | 97.86% | 97.86% | 97.86% | Large |
| PingAn AI Lab (Nanjing) | 6/26/2018 | 97.493% | 97.493% | 97.493% | Large |
| ULUFace | 5/6/2018 | 97.487% | 97.487% | 97.487% | Large |
| ULUFace | 5/7/2018 | 97.4869% | 97.4869% | 97.4869% | Large |
| Fiberhome AI Research Lab V2(Nanjing) | 8/28/2018 | 97.3378% | 97.3378% | 97.3378% | Large |
| MSU_Intsys | 5/16/2018 | 97.16% | 97.16% | 97.16% | Large |
| MTDP_ITC(Clean) | 4/17/2018 | 97.0807% | Large | ||
| FeelingTech | 5/18/2018 | 96.825% | 96.825% | 96.825% | Large |
| EM-DATA | 4/4/2018 | 96.653% | Large | ||
| SuningUS_AILab | 3/21/2018 | 96.2618947% | 96.2618947% | 96.2618947% | Large |
| Jian24 Vision | 5/8/2018 | 95.9156% | 95.9156% | 95.9156% | Large |
| KANKAN AI Lab | 5/23/2018 | 95.045% | Large | ||
| Kankan AI Lab | 4/24/2018 | 95.045% | Large | ||
| Fiberhome AI Research Lab(Nanjing) | 7/12/2018 | 94.343% | 94.343% | 94.343% | Large |
| CyberLink_mobile | 8/30/2018 | 94.093% | 94.093% | 94.093% | Large |
| StartDT-AI | 4/16/2018 | 93.8226% | Large | ||
| Intellivision | 2/11/2018 | 93.125% | 93.123% | 93.136% | Large |
| ULSee - Face Team | 3/27/2018 | 92.172% | Large | ||
| Vocord - deepVo V3 | 04/27/2017 | 91.763% | 91.711% | 91.704% | Large |
| MTDP_ITC | 12/21/2017 | 87.098% | 83.877% | 87.184% | Large |
| TUPUTECH | 12/22/2017 | 86.558% | 86.557% | 86.579% | Large |
| Video++ | 1/5/2018 | 85.74% | 85.737% | 85.735% | Large |
| THU CV-AI Lab | 12/12/2017 | 84.521% | 84.513% | 84.514% | Large |
| TencentAILab_FaceCNN_v1 | 9/21/2017 | 84.261% | 84.255% | 84.257% | Large |
| BingMMLab-v1 (non-cleaned data) | 4/10/2018 | 83.758% | Large | ||
| Orion Star Technology (no clean) | 3/21/2018 | 83.569% | Large | ||
| YouTu Lab (Tencent Best-Image) | 04/08/2017 | 83.29% | 83.267% | 83.295% | Large |
| OceanAI Tech | 12/15/2017 | 83.164% | 83.177% | 83.144% | Large |
| FaceTag V1 | 12/18/2017 | 82.411% | 82.376% | 82.364% | Large |
| Argus_v1 | 2/6/2018 | 81.437% | 81.424% | 81.438% | Large |
| Qsdream | 6/25/2018 | 81.354% | 81.354% | 81.354% | Large |
| Yang Sun | 06/05/2017 | 81.326% | 81.286% | 81.284% | Large |
| DeepSense V2 | 1/22/2017 | 81.298% | 81.298% | 81.298% | Large |
| iBug (Reported by Author) | 04/28/2017 | 80.277% | Small | ||
| Vocord-deepVo1.2 | 12/1/2016 | 80.258% | 80.195% | 80.241% | Large |
| Faceter Lab | 12/18/2017 | 79.426% | 79.367% | 79.356% | Large |
| Progressor | 09/13/2017 | 79.41% | 79.41% | 79.41% | Large |
| CVTE V2 | 1/27/2018 | 78.324% | 78.293% | 78.298% | Small |
| Fudan University - FUDAN-CS_SDS | 1/29/2017 | 77.982% | 78.006% | 77.99% | Small |
| GRCCV | 12/1/2016 | 77.677% | 77.021% | 77.147% | Small |
| XT-tech V2 | 08/30/2017 | 77.239% | 77.239% | 77.239% | Large |
| Beijing Faceall Co. - FaceAll V2 | 04/28/2017 | 76.661% | 76.643% | 76.607% | Small |
| SphereFace - Small | 12/1/2016 | 75.766% | 75.765% | 75.77% | Small |
| Vocord - DeepVo1 | 08/03/2016 | 75.127% | 75.093% | 75.125% | Large |
| DeepSense - Large | 07/31/2016 | 74.799% | 74.78% | 74.813% | Large |
| SIATMMLAB TencentVision | 12/1/2016 | 74.207% | 74.213% | 74.195% | Large |
| Shanghai Tech | 08/13/2016 | 74.049% | 74.032% | 74.02% | Large |
| CVTE | 08/30/2017 | 73.521% | 73.501% | 73.504% | Large |
| NTechLAB - facenx_large | 10/20/2015 | 73.3% | 73.309% | 73.287% | Large |
| ForceInfo | 04/07/2017 | 72.11% | 72.084% | 72.121% | Large |
| 3DiVi Company - tdvm V2 | 04/15/2017 | 71.742% | 71.727% | 71.703% | Large |
| DeepSense - Small | 07/31/2016 | 70.983% | 70.948% | 70.962% | Small |
| Google - FaceNet v8 | 10/23/2015 | 70.496% | 70.492% | 70.551% | Large |
| SIAT_MMLAB | 3/29/2016 | 65.233% | 65.223% | 65.229% | Small |
| Beijing Faceall Co. - FaceAll_Norm_1600 | 10/19/2015 | 64.803% | 64.798% | 64.826% | Large |
| Beijing Faceall Co. - FaceAll_1600 | 10/19/2015 | 63.977% | 63.962% | 63.993% | Large |
| Barebones_FR - cnn | 10/21/2015 | 59.363% | 59.379% | 59.389% | Small |
| NTechLAB - facenx_small | 10/20/2015 | 58.218% | 58.208% | 58.21% | Small |
| 3DiVi Company - tdvm6 | 10/27/2015 | 33.705% | 33.69% | 33.667% | Small |
| Joint Bayes | 10/20/2015 | 3.021% | 3.223% | 3.245% | Small |
| LBP | 10/20/2015 | 2.326% | 2.32% | 2.318% | Small |
| Uface | 4/26/2018 | 1.0% | Large | ||
| EM-DATA | 6/14/2018 | 0.982029% | 0.982029% | 0.982029% | Large |
Method Details
| Algorithm | Details |
|---|---|
| Orion Star Technology (clean) | We have trained three deep networks (ResNet-101, ResNet-152, ResNet-200) with joint softmax and triplet loss on MS-Celeb-1M (95K identities, 5.1M images), and the triplet part is trained by batch online hard negative mining with subspace learning. The features of all networks are concatenated to produce the final feature, whose dimension is set to be 256x3. For data processing, we use original large images and follow our own system by detection and alignment. Particularly, in evaluation, we have cleaned the FaceScrub and MegaFace with the code released by iBUG_DeepInsight. |
| Orion Star Technology (no clean) | Compared to our another submission named “Orion Star Technology (clean)”, the major difference is that no any data cleaning is adopted in evaluation. |
| SuningUS_AILab | This is a model ensembled by three different models using ResNet CNN and improved ResNet network, learned by a combined loss. A filtered MS-Celeb-1M and CASIA-Webface is used as the dataset. |
| ULSee - Face Team | Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://arxiv.org/abs/1604.02878 Large-Margin Softmax Loss for Convolutional Neural Networks https://arxiv.org/abs/1612.02295 A Discriminative Deep Feature Learning Approach for Face Recognition https://ydwen.github.io/papers/WenECCV16.pdf NormFace: L2 Hypersphere Embedding for Face Verification https://arxiv.org/abs/1704.06369 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 |
| SIATMMLAB TencentVision | Adopt the ensemble of very deep CNNs, learned by joint supervision (softmax loss, improved center loss, etc). Training data is a combination of public datasets (CAISA, VGG, CACD2000, etc) and private datasets. The total number of images is more than 2 million. |
| DeepSense - Small | Adopt a network of very deep ResNet CNNs, learned by combined supervision(identification loss(softmax loss), verification loss, triplet loss). |
| GRCCV | The algorithm consists of three parts: FCN - based fast face detection algorithm, pre-training ResNet CNN on classification task, weight tuning. Training set contains 273000 photos. Hardware: 8 x Tesla k80. |
| SphereFace - Small | SphereFace uses a novel approach to learn face features that are discriminative on a hypersphere manifold. The training data set we use in SphereFace is the publicly available CASIA-WebFace dataset which contains 490k images of nearly 10,500 individuals. |
| EM-DATA | arcface, https://github.com/deepinsight/insightface |
| StartDT-AI | we only use a single model trained on a ResNet-28 network joined with cosine loss and triplet loss on MS-Celeb-1M(74K identities, 4M images), refer to DeepVisage: Making face recognition simple yet with powerful generalization skills https://arxiv.org/abs/1703.08388 One-shot Face Recognition by Promoting Underrepresented Classes https://arxiv.org/abs/1707.05574v2 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063 |
| BingMMLab-v1 (non-cleaned data) | Compares to our submissions named “BingMMLab V1(cleaned data)”, the only difference is that no data cleaning is adopted in this evaluation. |
| BingMMLab V1(iBUG cleaned data) | We used knowledge graph to collect identities and then crawled Bing search engine to get high quality images, we filtered noises in 14M training data by clustering with weak face models, and then trained a DensetNet-69 (k=48) network with A-Softmax loss variants. In evaluation, we used the cleaned test set released by iBUG_DeepInsight. DenseNet https://arxiv.org/pdf/1608.06993v2.pdf A-Softmax and its variant: https://arxiv.org/pdf/1704.08063.pdf https://github.com/wy1iu/LargeMargin_Softmax_Loss/issues/13 |
| MTDP_ITC(Clean) | Angular Softmax Loss with Channel-wise Attention |
| Kankan AI Lab | We have trained our model on ResNet-152 with Additive Angular Margin Loss on combined dataset with MS-Celeb-1M and VggFace2, and cleaned the FaceScrub and MegaFace with the lists released by iBUG_DeepInsight. Deep Residual Learning for Image Recognition https://arxiv.org/abs/1512.03385 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 https://github.com/deepinsight/insightface VGGFace2: A dataset for recognising faces across pose and age https://arxiv.org/abs/1710.08092 MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition https://www.microsoft.com/en-us/research/wp-content/uploads/2016/08/MSCeleb-1M-a.pdf |
| TUPUTECH V1 (iBUG cleaned data) | We have trained ResNet models with a combined loss on MS-Celeb-1M. In evaluation, we have cleaned the FaceScrub and MegaFace with the code released by iBUG_DeepInsight. [iBUG_DeepInsight code](https://github.com/deepinsight/insightface) |
| TUPUTECH v2 | Compares to our submissions named “TUPUTECH v1 (clean)”, the only difference is data cleaning by TUPU is adopted in evaluation. |
| Uface | trained network with arcface loss. tried some different methods in preprocessing data.In evaluation, used the cleaned test set released by iBUG_DeepInsight. |
| ULUFace | Deep Residual Learning for Image Recognition https://arxiv.org/abs/1512.03385v1 MTCNN:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://arxiv.org/abs/1604.02878 FaceNet: A Unified Embedding for Face Recognition and Clustering https://arxiv.org/abs/1503.03832 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063 Additive Margin Softmax for Face Verification https://arxiv.org/abs/1801.05599v2 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698v1 |
| ULUFace | Deep Residual Learning for Image Recognition https://arxiv.org/abs/1512.03385v1 MTCNN:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://arxiv.org/abs/1604.02878 FaceNet: A Unified Embedding for Face Recognition and Clustering https://arxiv.org/abs/1503.03832 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063 Additive Margin Softmax for Face Verification https://arxiv.org/abs/1801.05599v2 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698v1 |
| Jian24 Vision | we only use a single model trained on a ResNet-101 network joined with cosine loss and triplet loss on MS-Celeb-1M(74K identities, 4M images), refer to Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://arxiv.org/abs/1604.02878 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063 A Discriminative Deep Feature Learning Approach for Face Recognition https://ydwen.github.io/papers/WenECCV16.pdf |
| sophon | using insightface with loss modification. |
| MSU_Intsys | Custom version of ArcFace. |
| FeelingTech | FeelingFace, which trained with cleaned MS-Celeb-1M dataset |
| KANKAN AI Lab | We have trained our model on ResNet-152 with Additive Angular Margin Loss on combined dataset with MS-Celeb-1M and VggFace2, and cleaned the FaceScrub and MegaFace with the lists released by iBUG_DeepInsight. Deep Residual Learning for Image Recognition https://arxiv.org/abs/1512.03385 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 https://github.com/deepinsight/insightface VGGFace2: A dataset for recognising faces across pose and age https://arxiv.org/abs/1710.08092 MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition https://www.microsoft.com/en-us/research/wp-content/uploads/2016/08/MSCeleb-1M-a.pdf |
| Sogou | We collected and filtered millions pictures from sogou pic search engine, and also used pictures date cleaned by DeepInsight. We trained multi model by different loss functions such as combined margin loss, margin loss with focal loss and so on. In some models we divided faces into different patches so we can get features represent local feature such as mouth and even teeth. We merge the features get from different models together as the final result. |
| SenseTime PureFace(clean) | We trained the deep residual attention network(attention-56) with A-softmax to learn the face feature. The training dataset is constructed by the novel dataset building techinique, which is critical for us to improve the performance of the model. The results are the cleaned test set performance released by iBUG_DeepInsight. Wang F, Jiang M, Qian C, et al. Residual attention network for image classification[J]. arXiv preprint arXiv:1704.06904, 2017. Deng J, Guo J, Zafeiriou S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition[J]. arXiv preprint arXiv:1801.07698, 2018. Liu W, Wen Y, Yu Z, et al. Sphereface: Deep hypersphere embedding for face recognition[C]//The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017, 1. |
| EM-DATA | arcface, https://github.com/deepinsight/insightface |
| ATLAB-FACEX (QINIU CLOUD) | A single deep Resnet model (the 'r100' configuration from insightface) trained with our own angular margin loss (an improved variant of A-Softmax, not published yet). The training set consists of nearly 6.2M images (about 96K identities). For MegaFace evaluation, we adopted the clean list released by iBUG_DeepInsight. insightface: https://github.com/deepinsight/insightface A-Softmax: https://arxiv.org/pdf/1704.08063.pdf |
| Qsdream | ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 |
| PingAn AI Lab (Nanjing) | This is a single model trained by a deep ResNet network on MS-Celeb-1M,learned by a cosine loss, refer to ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063 We used the noises list proposed by InsightFace, at https://github.com/deepinsight/insightface/tree/master/src/megaface |
| Fiberhome AI Research Lab(Nanjing) | mtcnn: Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://arxiv.org/abs/1604.02878 https://github.com/pangyupo/mxnet_mtcnn_face_detection ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 https://github.com/deepinsight/insightface |
| QINIU ATLAB - FaceX V1 (iBUG cleaned data) | This feature model is an ensemble of 3 deep Resnet models (the 'r100' and 'r152' configuration from insightface[1] ) trained with our own angular margin loss (an improved variant of A-Softmax[2] , not published yet). The training set consists of 7 Million images (about 188K identities). For evaluation, we adopted the clean list released by iBUG_DeepInsight[1] . Reference: [1] insightface: https://github.com/deepinsight/insightface [2] A-Softmax: https://arxiv.org/pdf/1704.08063.pdf |
| Visual Computing-Alibaba-V1(clean) | A single model (improved Resnet-152) is trained by the supervision of combined loss functions (A-Softmax loss, center loss, triplet loss et al) on MS-Celeb-1M (84 k identities, 5.2 M images). In evaluation, we use the cleaned FaceScrub and MegaFace released by iBUG_DeepInsight. |
| Beijing Faceall Co. & BUPT(iBug cleaned) | We have trained on the Faceall-msra celebrities dataset with over 4.4 million photos. We use 6 models to ensemble the training result and use cosine distance as the distance metrics. As for loss function, we adopt A-softmax and Additive Angular margin loss during training. We evaluate our result on the iBUG-cleaned version of megaface and facescrub list. Method reference: SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063 Additive Margin Softmax for Face Verification https://arxiv.org/abs/1801.05599v2 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698v1 |
| EI Networks | We build a training database of 120,000 identities and 12 million images with combination of public and private databases. We remove the overlap with Facescrub and Fgnet database from our training set. Three deep residual networks are trained (one resnet-150 like and two resnet-100 like) on 112x96 input image with multiple large margin loss functions. Each network is further finetuned using triplet loss. Output feature of three networks is concatenated and trained with metric learning for dimension reduction to a vector of size 512. |
| Uniview Technology | use the fusion model of resnet and googlenet |
| SRC-Beijing-FR(Samsung Research Institute China-Beijing) | An improved loss of sphereface with a large-scale training dataset. |
| 4paradigm | We have trained resnet101 model with large additive margin softmax loss on merged MS-Celeb-1M and Asian-Celeb and fine-tune the model with batchhard triplet loss . In evaluation, we cleaned the FaceScrub and MegaFace using noisy face images released by[1] [1]Deng J, Guo J, Zafeiriou S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition[J]. 2018. |
| 4paradigm | We have trained resnet101 model with combine large margin softmax loss on merged MS-Celeb-1M and Asian-Celeb and fine-tune the model with batchhard triplet loss . In evaluation, we cleaned the FaceScrub and MegaFace using the noises list proposed by InsightFace, at https://github.com/deepinsight/insightface/tree/master/src/megaface |
| Fiberhome AI Research Lab V2(Nanjing) | Compares to our submissions named “Fiberhome AI Research Lab ”,the differences are the following: 1.we changed the face alignment method. 2.we added private datasets to train 3.we adopted a RestNet-50 network joined with cosine loss and Additive Angular Margin Loss |
| CyberLink | Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html Deep Residual Learning for Image Recognition https://arxiv.org/abs/1512.03385v1 Additive Margin Softmax for Face Verification https://arxiv.org/abs/1801.05599v4 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698v1 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063v4 We used the noises list proposed by InsightFace, at https://github.com/deepinsight/insightface/tree/master/src/megaface |
| CyberLink_mobile | Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html MobileFaceNets: Efficient CNNs for Accurate Real-Time Face Verification on Mobile Devices https://arxiv.org/abs/1804.07573v4 Additive Margin Softmax for Face Verification https://arxiv.org/abs/1801.05599v4 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698v1 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063v4 We used the noises list proposed by InsightFace, at https://github.com/deepinsight/insightface/tree/master/src/megaface |
| cyberlink_resnet-v2 | Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html Deep Residual Learning for Image Recognition https://arxiv.org/abs/1512.03385v1 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698v1 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063v4 Additive Margin Softmax for Face Verification https://arxiv.org/abs/1801.05599v4 We used the noises list proposed by InsightFace, at https://github.com/deepinsight/insightface/tree/master/src/megaface |
| Sogou AIGROUP - SFace | We collected and filtered millions pictures from sogou pic search engine and mining one hundred thousand hard negative sample, all data are cleaned by DeepInsight. We trained multi model by different loss functions such as combined margin loss, margin loss with focal loss and so on. In some models we divided faces into different patches so we can get features represent local feature, especially the tooth similarity model. We merge the features get from different models together as the final result. |
| ICARE_FACE_V1 | We have trained our model based on a deep convolutional neural network(ResNet101) with Additive Margin Softmax.We have semi-automatically cleaned the training dataset MSCeleb-1M.Particularly,in evaluation,we cleaned the FaceScrub and MegaFace with the lists released by iBUG_DeepInsight. Additive Margin Softmax for Face Verification https://arxiv.org/abs/1801.05599 Insightface clean list https://github.com/deepinsight/insightface |

- - uses large training set
Set 1
Set 1
- - uses large training set
Set 2
Set 2
- - uses large training set
Set 3
Set 3
Identification Rank vs. Rank
| Algorithm | Date Submitted | Set 1 | Set 2 | Set 3 | Data Set Size |
|---|---|---|---|---|---|
| Sogou AIGROUP - SFace | 9/5/2018 | 99.939% | 99.939% | 99.939% | Large |
| SRC-Beijing-FR(Samsung Research Institute China-Beijing) | 8/15/2018 | 99.888% | 99.888% | 99.888% | Large |
| SenseTime PureFace(clean) | 6/13/2018 | 99.801% | 99.801% | 99.801% | Large |
| EI Networks | 8/10/2018 | 99.414% | 99.414% | 99.414% | Large |
| ICARE_FACE_V1 | 9/13/2018 | 99.3198% | 99.3198% | 99.3198% | Large |
| Sogou | 6/12/2018 | 99.2% | 99.2% | 99.2% | Large |
| Uniview Technology | 8/12/2018 | 99.196% | Large | ||
| QINIU ATLAB - FaceX V1 (iBUG cleaned data) | 7/23/2018 | 99.132% | 99.132% | 99.132% | Large |
| Visual Computing-Alibaba-V1(clean) | 8/6/2018 | 99.126% | Large | ||
| TUPUTECH V1 (iBUG cleaned data) | 4/24/2018 | 99.087% | Large | ||
| TUPUTECH v2 | 4/25/2018 | 99.078% | Large | ||
| BingMMLab V1(iBUG cleaned data) | 4/10/2018 | 98.998% | Large | ||
| ATLAB-FACEX (QINIU CLOUD) | 6/23/2018 | 98.61% | 98.61% | 98.61% | Large |
| cyberlink_resnet-v2 | 9/5/2018 | 98.455% | 98.455% | 98.455% | Large |
| CyberLink | 8/30/2018 | 98.448% | 98.448% | 98.448% | Large |
| Orion Star Technology (clean) | 3/21/2018 | 98.355% | Large | ||
| Beijing Faceall Co. & BUPT(iBug cleaned) | 8/8/2018 | 98.093% | 98.093% | 98.093% | Large |
| iBUG_DeepInsight | 2/8/2018 | 98.063% | 98.058% | 98.053% | Large |
| 4paradigm | 8/24/2018 | 97.977% | Large | ||
| 4paradigm | 8/18/2018 | 97.977% | Large | ||
| sophon | 5/15/2018 | 97.86% | 97.86% | 97.86% | Large |
| PingAn AI Lab (Nanjing) | 6/26/2018 | 97.493% | 97.493% | 97.493% | Large |
| ULUFace | 5/6/2018 | 97.487% | 97.487% | 97.487% | Large |
| ULUFace | 5/7/2018 | 97.4869% | 97.4869% | 97.4869% | Large |
| Fiberhome AI Research Lab V2(Nanjing) | 8/28/2018 | 97.3378% | 97.3378% | 97.3378% | Large |
| MSU_Intsys | 5/16/2018 | 97.16% | 97.16% | 97.16% | Large |
| MTDP_ITC(Clean) | 4/17/2018 | 97.0807% | Large | ||
| FeelingTech | 5/18/2018 | 96.825% | 96.825% | 96.825% | Large |
| EM-DATA | 4/4/2018 | 96.653% | Large | ||
| SuningUS_AILab | 3/21/2018 | 96.2618947% | 96.2618947% | 96.2618947% | Large |
| Jian24 Vision | 5/8/2018 | 95.9156% | 95.9156% | 95.9156% | Large |
| KANKAN AI Lab | 5/23/2018 | 95.045% | Large | ||
| Kankan AI Lab | 4/24/2018 | 95.045% | Large | ||
| Fiberhome AI Research Lab(Nanjing) | 7/12/2018 | 94.343% | 94.343% | 94.343% | Large |
| CyberLink_mobile | 8/30/2018 | 94.093% | 94.093% | 94.093% | Large |
| StartDT-AI | 4/16/2018 | 93.8226% | Large | ||
| Intellivision | 2/11/2018 | 93.125% | 93.123% | 93.136% | Large |
| ULSee - Face Team | 3/27/2018 | 92.172% | Large | ||
| Vocord - deepVo V3 | 04/27/2017 | 91.763% | 91.711% | 91.704% | Large |
| MTDP_ITC | 12/21/2017 | 87.098% | 83.877% | 87.184% | Large |
| TUPUTECH | 12/22/2017 | 86.558% | 86.557% | 86.579% | Large |
| Video++ | 1/5/2018 | 85.74% | 85.737% | 85.735% | Large |
| THU CV-AI Lab | 12/12/2017 | 84.521% | 84.513% | 84.514% | Large |
| TencentAILab_FaceCNN_v1 | 9/21/2017 | 84.261% | 84.255% | 84.257% | Large |
| BingMMLab-v1 (non-cleaned data) | 4/10/2018 | 83.758% | Large | ||
| Orion Star Technology (no clean) | 3/21/2018 | 83.569% | Large | ||
| YouTu Lab (Tencent Best-Image) | 04/08/2017 | 83.29% | 83.267% | 83.295% | Large |
| OceanAI Tech | 12/15/2017 | 83.164% | 83.177% | 83.144% | Large |
| FaceTag V1 | 12/18/2017 | 82.411% | 82.376% | 82.364% | Large |
| Argus_v1 | 2/6/2018 | 81.437% | 81.424% | 81.438% | Large |
| Qsdream | 6/25/2018 | 81.354% | 81.354% | 81.354% | Large |
| Yang Sun | 06/05/2017 | 81.326% | 81.286% | 81.284% | Large |
| DeepSense V2 | 1/22/2017 | 81.298% | 81.298% | 81.298% | Large |
| iBug (Reported by Author) | 04/28/2017 | 80.277% | Small | ||
| Vocord-deepVo1.2 | 12/1/2016 | 80.258% | 80.195% | 80.241% | Large |
| Faceter Lab | 12/18/2017 | 79.426% | 79.367% | 79.356% | Large |
| Progressor | 09/13/2017 | 79.41% | 79.41% | 79.41% | Large |
| CVTE V2 | 1/27/2018 | 78.324% | 78.293% | 78.298% | Small |
| Fudan University - FUDAN-CS_SDS | 1/29/2017 | 77.982% | 78.006% | 77.99% | Small |
| GRCCV | 12/1/2016 | 77.677% | 77.021% | 77.147% | Small |
| XT-tech V2 | 08/30/2017 | 77.239% | 77.239% | 77.239% | Large |
| Beijing Faceall Co. - FaceAll V2 | 04/28/2017 | 76.661% | 76.643% | 76.607% | Small |
| SphereFace - Small | 12/1/2016 | 75.766% | 75.765% | 75.77% | Small |
| Vocord - DeepVo1 | 08/03/2016 | 75.127% | 75.093% | 75.125% | Large |
| DeepSense - Large | 07/31/2016 | 74.799% | 74.78% | 74.813% | Large |
| SIATMMLAB TencentVision | 12/1/2016 | 74.207% | 74.213% | 74.195% | Large |
| Shanghai Tech | 08/13/2016 | 74.049% | 74.032% | 74.02% | Large |
| CVTE | 08/30/2017 | 73.521% | 73.501% | 73.504% | Large |
| NTechLAB - facenx_large | 10/20/2015 | 73.3% | 73.309% | 73.287% | Large |
| ForceInfo | 04/07/2017 | 72.11% | 72.084% | 72.121% | Large |
| 3DiVi Company - tdvm V2 | 04/15/2017 | 71.742% | 71.727% | 71.703% | Large |
| DeepSense - Small | 07/31/2016 | 70.983% | 70.948% | 70.962% | Small |
| Google - FaceNet v8 | 10/23/2015 | 70.496% | 70.492% | 70.551% | Large |
| SIAT_MMLAB | 3/29/2016 | 65.233% | 65.223% | 65.229% | Small |
| Beijing Faceall Co. - FaceAll_Norm_1600 | 10/19/2015 | 64.803% | 64.798% | 64.826% | Large |
| Beijing Faceall Co. - FaceAll_1600 | 10/19/2015 | 63.977% | 63.962% | 63.993% | Large |
| Barebones_FR - cnn | 10/21/2015 | 59.363% | 59.379% | 59.389% | Small |
| NTechLAB - facenx_small | 10/20/2015 | 58.218% | 58.208% | 58.21% | Small |
| 3DiVi Company - tdvm6 | 10/27/2015 | 33.705% | 33.69% | 33.667% | Small |
| Joint Bayes | 10/20/2015 | 3.021% | 3.223% | 3.245% | Small |
| LBP | 10/20/2015 | 2.326% | 2.32% | 2.318% | Small |
| Uface | 4/26/2018 | 1.0% | Large | ||
| EM-DATA | 6/14/2018 | 0.982029% | 0.982029% | 0.982029% | Large |
Method Details
| Algorithm | Details |
|---|---|
| Orion Star Technology (clean) | We have trained three deep networks (ResNet-101, ResNet-152, ResNet-200) with joint softmax and triplet loss on MS-Celeb-1M (95K identities, 5.1M images), and the triplet part is trained by batch online hard negative mining with subspace learning. The features of all networks are concatenated to produce the final feature, whose dimension is set to be 256x3. For data processing, we use original large images and follow our own system by detection and alignment. Particularly, in evaluation, we have cleaned the FaceScrub and MegaFace with the code released by iBUG_DeepInsight. |
| Orion Star Technology (no clean) | Compared to our another submission named “Orion Star Technology (clean)”, the major difference is that no any data cleaning is adopted in evaluation. |
| SuningUS_AILab | This is a model ensembled by three different models using ResNet CNN and improved ResNet network, learned by a combined loss. A filtered MS-Celeb-1M and CASIA-Webface is used as the dataset. |
| ULSee - Face Team | Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://arxiv.org/abs/1604.02878 Large-Margin Softmax Loss for Convolutional Neural Networks https://arxiv.org/abs/1612.02295 A Discriminative Deep Feature Learning Approach for Face Recognition https://ydwen.github.io/papers/WenECCV16.pdf NormFace: L2 Hypersphere Embedding for Face Verification https://arxiv.org/abs/1704.06369 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 |
| SIATMMLAB TencentVision | Adopt the ensemble of very deep CNNs, learned by joint supervision (softmax loss, improved center loss, etc). Training data is a combination of public datasets (CAISA, VGG, CACD2000, etc) and private datasets. The total number of images is more than 2 million. |
| DeepSense - Small | Adopt a network of very deep ResNet CNNs, learned by combined supervision(identification loss(softmax loss), verification loss, triplet loss). |
| GRCCV | The algorithm consists of three parts: FCN - based fast face detection algorithm, pre-training ResNet CNN on classification task, weight tuning. Training set contains 273000 photos. Hardware: 8 x Tesla k80. |
| SphereFace - Small | SphereFace uses a novel approach to learn face features that are discriminative on a hypersphere manifold. The training data set we use in SphereFace is the publicly available CASIA-WebFace dataset which contains 490k images of nearly 10,500 individuals. |
| EM-DATA | arcface, https://github.com/deepinsight/insightface |
| StartDT-AI | we only use a single model trained on a ResNet-28 network joined with cosine loss and triplet loss on MS-Celeb-1M(74K identities, 4M images), refer to DeepVisage: Making face recognition simple yet with powerful generalization skills https://arxiv.org/abs/1703.08388 One-shot Face Recognition by Promoting Underrepresented Classes https://arxiv.org/abs/1707.05574v2 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063 |
| BingMMLab-v1 (non-cleaned data) | Compares to our submissions named “BingMMLab V1(cleaned data)”, the only difference is that no data cleaning is adopted in this evaluation. |
| BingMMLab V1(iBUG cleaned data) | We used knowledge graph to collect identities and then crawled Bing search engine to get high quality images, we filtered noises in 14M training data by clustering with weak face models, and then trained a DensetNet-69 (k=48) network with A-Softmax loss variants. In evaluation, we used the cleaned test set released by iBUG_DeepInsight. DenseNet https://arxiv.org/pdf/1608.06993v2.pdf A-Softmax and its variant: https://arxiv.org/pdf/1704.08063.pdf https://github.com/wy1iu/LargeMargin_Softmax_Loss/issues/13 |
| MTDP_ITC(Clean) | Angular Softmax Loss with Channel-wise Attention |
| Kankan AI Lab | We have trained our model on ResNet-152 with Additive Angular Margin Loss on combined dataset with MS-Celeb-1M and VggFace2, and cleaned the FaceScrub and MegaFace with the lists released by iBUG_DeepInsight. Deep Residual Learning for Image Recognition https://arxiv.org/abs/1512.03385 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 https://github.com/deepinsight/insightface VGGFace2: A dataset for recognising faces across pose and age https://arxiv.org/abs/1710.08092 MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition https://www.microsoft.com/en-us/research/wp-content/uploads/2016/08/MSCeleb-1M-a.pdf |
| TUPUTECH V1 (iBUG cleaned data) | We have trained ResNet models with a combined loss on MS-Celeb-1M. In evaluation, we have cleaned the FaceScrub and MegaFace with the code released by iBUG_DeepInsight. [iBUG_DeepInsight code](https://github.com/deepinsight/insightface) |
| TUPUTECH v2 | Compares to our submissions named “TUPUTECH v1 (clean)”, the only difference is data cleaning by TUPU is adopted in evaluation. |
| Uface | trained network with arcface loss. tried some different methods in preprocessing data.In evaluation, used the cleaned test set released by iBUG_DeepInsight. |
| ULUFace | Deep Residual Learning for Image Recognition https://arxiv.org/abs/1512.03385v1 MTCNN:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://arxiv.org/abs/1604.02878 FaceNet: A Unified Embedding for Face Recognition and Clustering https://arxiv.org/abs/1503.03832 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063 Additive Margin Softmax for Face Verification https://arxiv.org/abs/1801.05599v2 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698v1 |
| ULUFace | Deep Residual Learning for Image Recognition https://arxiv.org/abs/1512.03385v1 MTCNN:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://arxiv.org/abs/1604.02878 FaceNet: A Unified Embedding for Face Recognition and Clustering https://arxiv.org/abs/1503.03832 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063 Additive Margin Softmax for Face Verification https://arxiv.org/abs/1801.05599v2 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698v1 |
| Jian24 Vision | we only use a single model trained on a ResNet-101 network joined with cosine loss and triplet loss on MS-Celeb-1M(74K identities, 4M images), refer to Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://arxiv.org/abs/1604.02878 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063 A Discriminative Deep Feature Learning Approach for Face Recognition https://ydwen.github.io/papers/WenECCV16.pdf |
| sophon | using insightface with loss modification. |
| MSU_Intsys | Custom version of ArcFace. |
| FeelingTech | FeelingFace, which trained with cleaned MS-Celeb-1M dataset |
| KANKAN AI Lab | We have trained our model on ResNet-152 with Additive Angular Margin Loss on combined dataset with MS-Celeb-1M and VggFace2, and cleaned the FaceScrub and MegaFace with the lists released by iBUG_DeepInsight. Deep Residual Learning for Image Recognition https://arxiv.org/abs/1512.03385 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 https://github.com/deepinsight/insightface VGGFace2: A dataset for recognising faces across pose and age https://arxiv.org/abs/1710.08092 MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition https://www.microsoft.com/en-us/research/wp-content/uploads/2016/08/MSCeleb-1M-a.pdf |
| Sogou | We collected and filtered millions pictures from sogou pic search engine, and also used pictures date cleaned by DeepInsight. We trained multi model by different loss functions such as combined margin loss, margin loss with focal loss and so on. In some models we divided faces into different patches so we can get features represent local feature such as mouth and even teeth. We merge the features get from different models together as the final result. |
| SenseTime PureFace(clean) | We trained the deep residual attention network(attention-56) with A-softmax to learn the face feature. The training dataset is constructed by the novel dataset building techinique, which is critical for us to improve the performance of the model. The results are the cleaned test set performance released by iBUG_DeepInsight. Wang F, Jiang M, Qian C, et al. Residual attention network for image classification[J]. arXiv preprint arXiv:1704.06904, 2017. Deng J, Guo J, Zafeiriou S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition[J]. arXiv preprint arXiv:1801.07698, 2018. Liu W, Wen Y, Yu Z, et al. Sphereface: Deep hypersphere embedding for face recognition[C]//The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017, 1. |
| EM-DATA | arcface, https://github.com/deepinsight/insightface |
| ATLAB-FACEX (QINIU CLOUD) | A single deep Resnet model (the 'r100' configuration from insightface) trained with our own angular margin loss (an improved variant of A-Softmax, not published yet). The training set consists of nearly 6.2M images (about 96K identities). For MegaFace evaluation, we adopted the clean list released by iBUG_DeepInsight. insightface: https://github.com/deepinsight/insightface A-Softmax: https://arxiv.org/pdf/1704.08063.pdf |
| Qsdream | ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 |
| PingAn AI Lab (Nanjing) | This is a single model trained by a deep ResNet network on MS-Celeb-1M,learned by a cosine loss, refer to ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063 We used the noises list proposed by InsightFace, at https://github.com/deepinsight/insightface/tree/master/src/megaface |
| Fiberhome AI Research Lab(Nanjing) | mtcnn: Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://arxiv.org/abs/1604.02878 https://github.com/pangyupo/mxnet_mtcnn_face_detection ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698 https://github.com/deepinsight/insightface |
| QINIU ATLAB - FaceX V1 (iBUG cleaned data) | This feature model is an ensemble of 3 deep Resnet models (the 'r100' and 'r152' configuration from insightface[1] ) trained with our own angular margin loss (an improved variant of A-Softmax[2] , not published yet). The training set consists of 7 Million images (about 188K identities). For evaluation, we adopted the clean list released by iBUG_DeepInsight[1] . Reference: [1] insightface: https://github.com/deepinsight/insightface [2] A-Softmax: https://arxiv.org/pdf/1704.08063.pdf |
| Visual Computing-Alibaba-V1(clean) | A single model (improved Resnet-152) is trained by the supervision of combined loss functions (A-Softmax loss, center loss, triplet loss et al) on MS-Celeb-1M (84 k identities, 5.2 M images). In evaluation, we use the cleaned FaceScrub and MegaFace released by iBUG_DeepInsight. |
| Beijing Faceall Co. & BUPT(iBug cleaned) | We have trained on the Faceall-msra celebrities dataset with over 4.4 million photos. We use 6 models to ensemble the training result and use cosine distance as the distance metrics. As for loss function, we adopt A-softmax and Additive Angular margin loss during training. We evaluate our result on the iBUG-cleaned version of megaface and facescrub list. Method reference: SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063 Additive Margin Softmax for Face Verification https://arxiv.org/abs/1801.05599v2 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698v1 |
| EI Networks | We build a training database of 120,000 identities and 12 million images with combination of public and private databases. We remove the overlap with Facescrub and Fgnet database from our training set. Three deep residual networks are trained (one resnet-150 like and two resnet-100 like) on 112x96 input image with multiple large margin loss functions. Each network is further finetuned using triplet loss. Output feature of three networks is concatenated and trained with metric learning for dimension reduction to a vector of size 512. |
| Uniview Technology | use the fusion model of resnet and googlenet |
| SRC-Beijing-FR(Samsung Research Institute China-Beijing) | An improved loss of sphereface with a large-scale training dataset. |
| 4paradigm | We have trained resnet101 model with large additive margin softmax loss on merged MS-Celeb-1M and Asian-Celeb and fine-tune the model with batchhard triplet loss . In evaluation, we cleaned the FaceScrub and MegaFace using noisy face images released by[1] [1]Deng J, Guo J, Zafeiriou S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition[J]. 2018. |
| 4paradigm | We have trained resnet101 model with combine large margin softmax loss on merged MS-Celeb-1M and Asian-Celeb and fine-tune the model with batchhard triplet loss . In evaluation, we cleaned the FaceScrub and MegaFace using the noises list proposed by InsightFace, at https://github.com/deepinsight/insightface/tree/master/src/megaface |
| Fiberhome AI Research Lab V2(Nanjing) | Compares to our submissions named “Fiberhome AI Research Lab ”,the differences are the following: 1.we changed the face alignment method. 2.we added private datasets to train 3.we adopted a RestNet-50 network joined with cosine loss and Additive Angular Margin Loss |
| CyberLink | Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html Deep Residual Learning for Image Recognition https://arxiv.org/abs/1512.03385v1 Additive Margin Softmax for Face Verification https://arxiv.org/abs/1801.05599v4 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698v1 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063v4 We used the noises list proposed by InsightFace, at https://github.com/deepinsight/insightface/tree/master/src/megaface |
| CyberLink_mobile | Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html MobileFaceNets: Efficient CNNs for Accurate Real-Time Face Verification on Mobile Devices https://arxiv.org/abs/1804.07573v4 Additive Margin Softmax for Face Verification https://arxiv.org/abs/1801.05599v4 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698v1 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063v4 We used the noises list proposed by InsightFace, at https://github.com/deepinsight/insightface/tree/master/src/megaface |
| cyberlink_resnet-v2 | Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html Deep Residual Learning for Image Recognition https://arxiv.org/abs/1512.03385v1 ArcFace: Additive Angular Margin Loss for Deep Face Recognition https://arxiv.org/abs/1801.07698v1 SphereFace: Deep Hypersphere Embedding for Face Recognition https://arxiv.org/abs/1704.08063v4 Additive Margin Softmax for Face Verification https://arxiv.org/abs/1801.05599v4 We used the noises list proposed by InsightFace, at https://github.com/deepinsight/insightface/tree/master/src/megaface |
| Sogou AIGROUP - SFace | We collected and filtered millions pictures from sogou pic search engine and mining one hundred thousand hard negative sample, all data are cleaned by DeepInsight. We trained multi model by different loss functions such as combined margin loss, margin loss with focal loss and so on. In some models we divided faces into different patches so we can get features represent local feature, especially the tooth similarity model. We merge the features get from different models together as the final result. |
| ICARE_FACE_V1 | We have trained our model based on a deep convolutional neural network(ResNet101) with Additive Margin Softmax.We have semi-automatically cleaned the training dataset MSCeleb-1M.Particularly,in evaluation,we cleaned the FaceScrub and MegaFace with the lists released by iBUG_DeepInsight. Additive Margin Softmax for Face Verification https://arxiv.org/abs/1801.05599 Insightface clean list https://github.com/deepinsight/insightface |
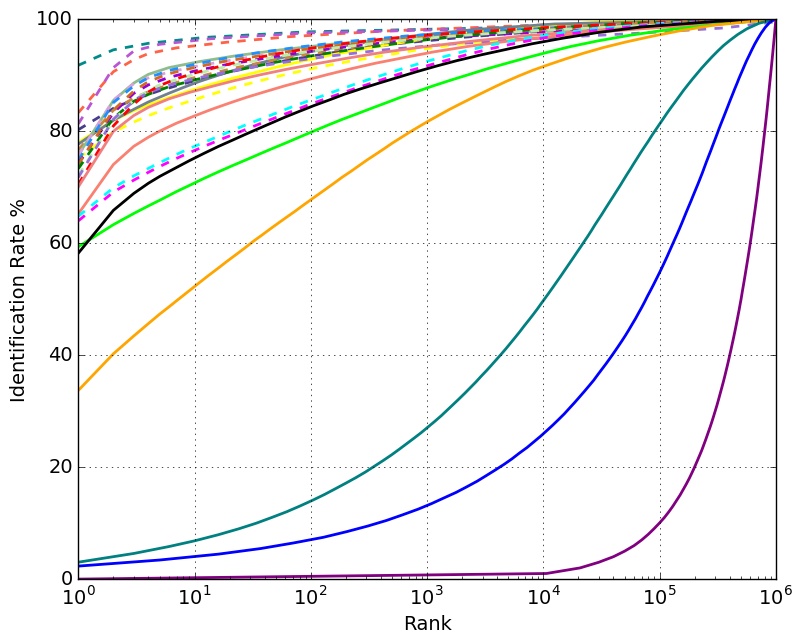
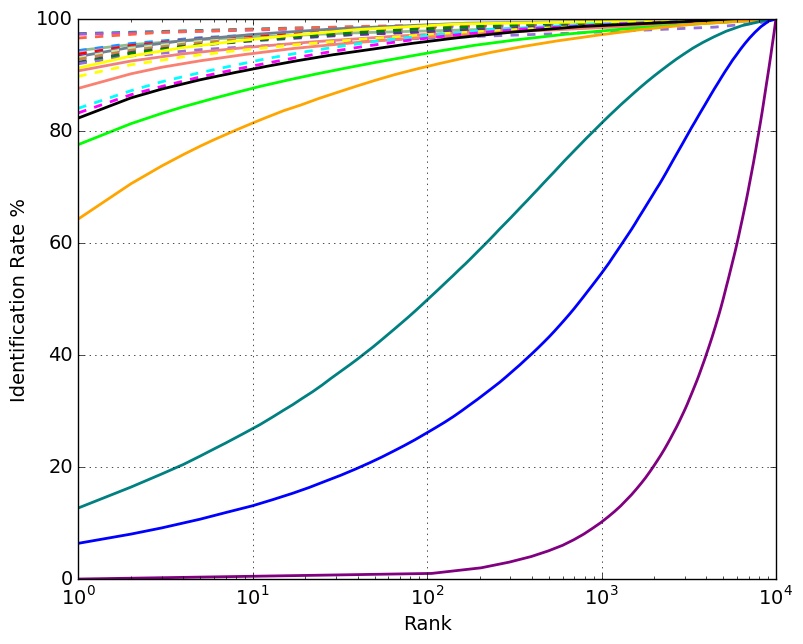
Identification Performance with 1 Million Distractors
Identification Performance with 10K Distractors
- - uses large training set
Set 1
Set 1
- - uses large training set
Set 2
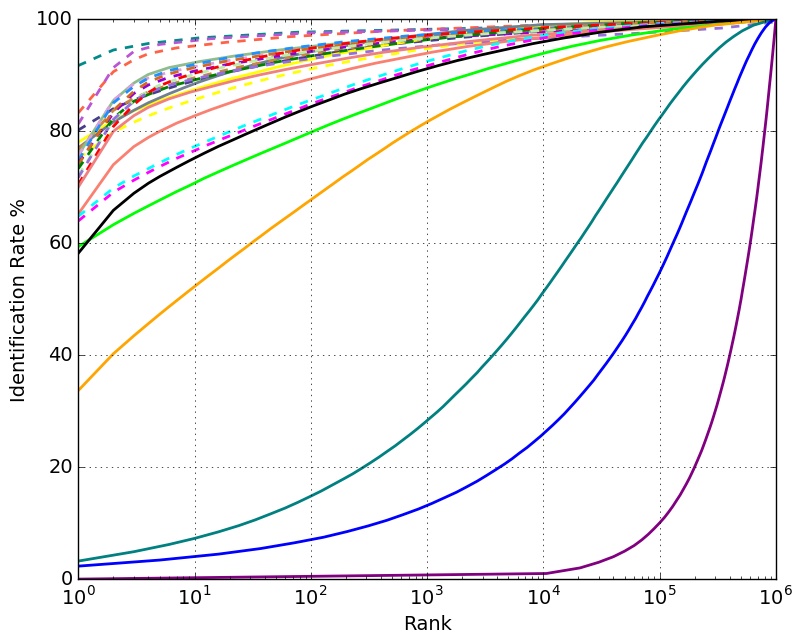
Set 2
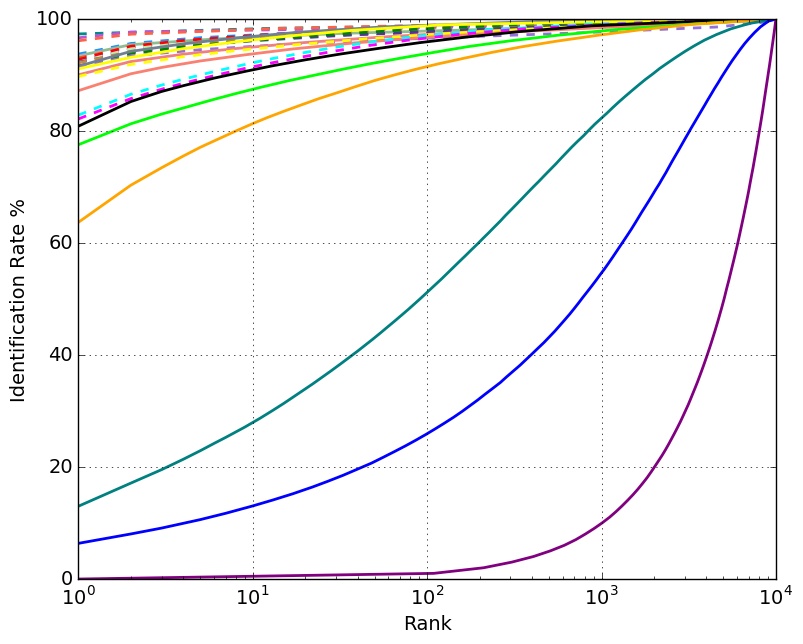
- - uses large training set
Set 3
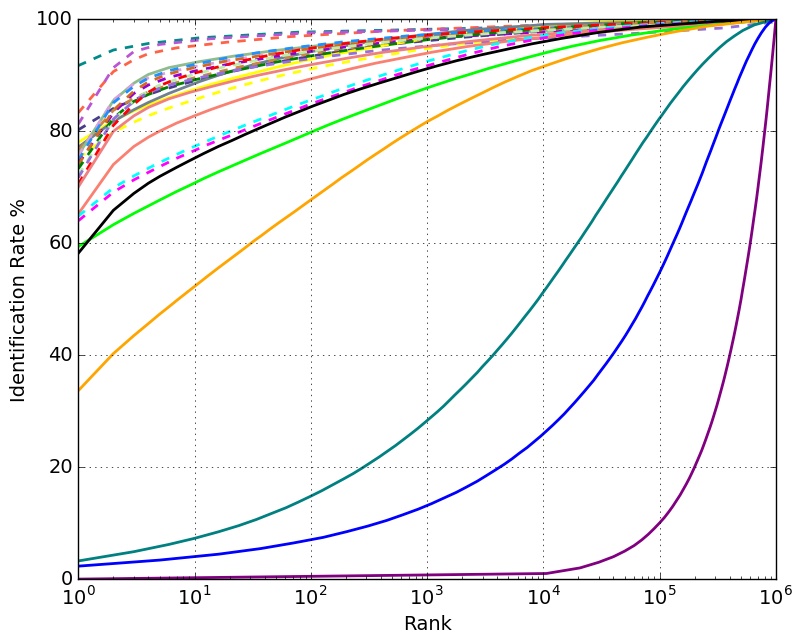
Set 3
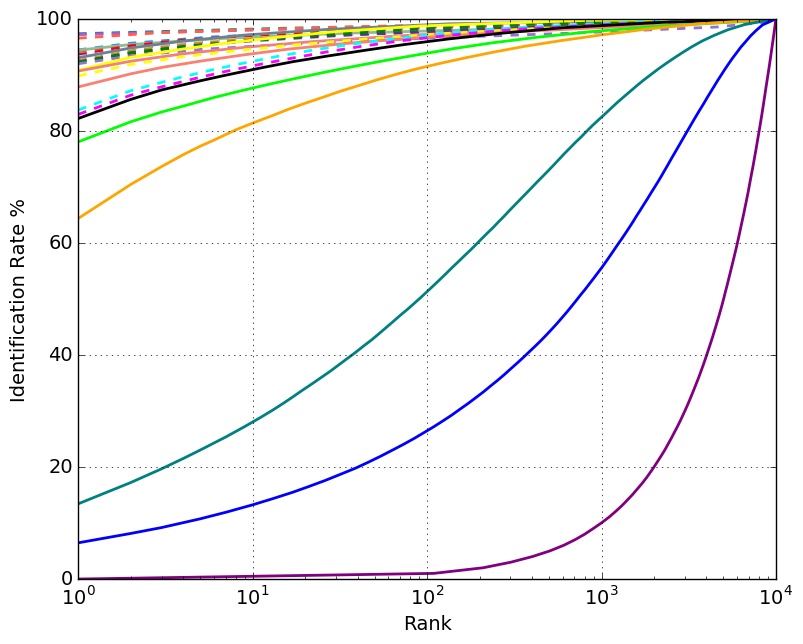
Verification
| Algorithm | Date Submitted | Set 1 | Set 2 | Set 3 | Data Set Size |
|---|---|---|---|---|---|
| Sogou AIGROUP - SFace | 9/5/2018 | 99.939% | 99.939% | 99.939% | Large |
| SRC-Beijing-FR(Samsung Research Institute China-Beijing) | 8/15/2018 | 99.8% | 99.8% | 99.8% | Large |
| SenseTime PureFace(clean) | 6/13/2018 | 99.626% | 99.626% | 99.626% | Large |
| ICARE_FACE_V1 | 9/13/2018 | 99.49% | 99.49% | 99.49% | Large |
| BingMMLab V1(iBUG cleaned data) | 4/10/2018 | 99.487% | 99.487% | 99.487% | Large |
| Visual Computing-Alibaba-V1(clean) | 8/6/2018 | 99.465% | Large | ||
| EI Networks | 8/10/2018 | 99.286% | 99.286% | 99.286% | Large |
| Uniview Technology | 8/12/2018 | 99.196% | Large | ||
| QINIU ATLAB - FaceX V1 (iBUG cleaned data) | 7/23/2018 | 99.155% | 99.155% | 99.155% | Large |
| iBUG_DeepInsight | 2/8/2018 | 98.948% | 98.948% | 99.008% | Large |
| ATLAB-FACEX (QINIU CLOUD) | 6/23/2018 | 98.69% | 98.69% | 98.69% | Large |
| cyberlink_resnet-v2 | 9/5/2018 | 98.406% | 98.406% | 98.406% | Large |
| CyberLink | 8/30/2018 | 98.291% | 98.291% | 98.291% | Large |
| BingMMLab-v1 (non-cleaned data) | 4/10/2018 | 98.279% | 98.279% | 98.279% | Large |
| 4paradigm | 8/18/2018 | 98.2523% | Large | ||
| TencentAILab_FaceCNN_v1 | 9/21/2017 | 97.961% | 97.961% | 97.961% | Large |
| sophon | 5/15/2018 | 97.86% | 97.86% | 97.86% | Large |
| Fiberhome AI Research Lab V2(Nanjing) | 8/28/2018 | 97.578% | 97.578% | 97.578% | Large |
| MSU_Intsys | 5/16/2018 | 97.56% | 97.56% | 97.56% | Large |
| ULUFace | 5/6/2018 | 97.487% | 97.487% | 97.487% | Large |
| ULUFace | 5/7/2018 | 97.4869% | 97.4869% | 97.4869% | Large |
| MTDP_ITC(Clean) | 4/17/2018 | 97.438% | 97.438% | 97.438% | Large |
| PingAn AI Lab (Nanjing) | 6/26/2018 | 97.437% | 97.437% | 97.437% | Large |
| FaceTag V1 | 12/18/2017 | 97.163% | 97.163% | 97.163% | Large |
| FeelingTech | 5/18/2018 | 97.104% | 97.104% | 97.104% | Large |
| Argus_v1 | 2/6/2018 | 96.66% | 96.65% | 96.65% | Large |
| EM-DATA | 4/4/2018 | 96.653% | 96.653% | 96.653% | Large |
| SuningUS_AILab | 3/21/2018 | 96.19355202% | 96.19355202% | 96.19355202% | Large |
| DeepSense V2 | 1/22/2017 | 95.993% | 95.993% | 94.984% | Large |
| Jian24 Vision | 5/8/2018 | 95.9156% | 95.9156% | 95.9156% | Large |
| Beijing Faceall Co. & BUPT(iBug cleaned) | 8/8/2018 | 95.795% | 95.795% | 95.795% | Large |
| Fiberhome AI Research Lab(Nanjing) | 7/12/2018 | 95.77% | 95.77% | 95.77% | Large |
| Yang Sun | 06/05/2017 | 95.178% | 96.179% | 96.187% | Large |
| Vocord - deepVo V3 | 04/27/2017 | 94.963% | 94.963% | 94.963% | Large |
| Video++ | 1/5/2018 | 94.89% | 94.89% | 94.89% | Large |
| Intellivision | 2/11/2018 | 94.786% | 94.786% | 94.786% | Large |
| Faceter Lab | 12/18/2017 | 94.749% | 94.749% | 94.749% | Large |
| CVTE V2 | 1/27/2018 | 94.417% | 94.417% | 94.417% | Small |
| CyberLink_mobile | 8/30/2018 | 94.123% | 94.123% | 94.123% | Large |
| StartDT-AI | 4/16/2018 | 93.8226% | 93.8226% | 93.8226% | Large |
| XT-tech V2 | 08/30/2017 | 93.695% | 93.695% | 93.695% | Large |
| THU CV-AI Lab | 12/12/2017 | 93.293% | 93.293% | 93.293% | Large |
| ULSee - Face Team | 3/27/2018 | 93.235% | Large | ||
| iBug (Reported by Author) | 04/28/2017 | 92.639% | Small | ||
| YouTu Lab (Tencent Best-Image) | 04/08/2017 | 91.34% | 91.34% | 91.34% | Large |
| SphereFace - Small | 12/1/2016 | 90.045% | 89.355% | 90.045% | Small |
| TUPUTECH | 12/22/2017 | 88.726% | 88.726% | 88.726% | Large |
| Progressor | 09/13/2017 | 88.59% | 85.59% | 85.59% | Large |
| DeepSense - Large | 07/31/2016 | 87.764% | 87.764% | 87.764% | Large |
| SIATMMLAB TencentVision | 12/1/2016 | 87.272% | 87.021% | 87.021% | Large |
| Google - FaceNet v8 | 10/23/2015 | 86.473% | 86.386% | 86.473% | Large |
| Shanghai Tech | 08/13/2016 | 86.369% | 86.369% | 86.369% | Large |
| ForceInfo | 04/07/2017 | 85.918% | 85.619% | 85.619% | Large |
| OceanAI Tech | 12/15/2017 | 85.86% | 85.86% | 85.891% | Large |
| CVTE | 08/30/2017 | 85.563% | 85.563% | 85.563% | Large |
| 3DiVi Company - tdvm V2 | 04/15/2017 | 85.411% | 85.411% | 85.411% | Large |
| NTechLAB - facenx_large | 10/20/2015 | 85.081% | 85.081% | 85.081% | Large |
| DeepSense - Small | 07/31/2016 | 82.851% | 82.851% | 82.851% | Small |
| Qsdream | 6/25/2018 | 81.354% | 81.354% | 81.354% | Large |
| Fudan University - FUDAN-CS_SDS | 1/29/2017 | 79.199% | 79.199% | 79.199% | Small |
| Beijing Faceall Co. - FaceAll V2 | 04/28/2017 | 77.607% | 77.607% | 77.607% | Small |
| Vocord-deepVo1.2 | 12/1/2016 | 77.143% | 77.143% | 77.143% | Large |
| SIAT_MMLAB | 3/29/2016 | 76.72% | 76.72% | 76.72% | Small |
| GRCCV | 12/1/2016 | 74.887% | 74.887% | 75.918% | Small |
| Vocord - DeepVo1 | 08/03/2016 | 67.318% | 67.318% | 67.318% | Large |
| Beijing Faceall Co. - FaceAll_Norm_1600 | 10/19/2015 | 67.118% | 67.118% | 67.118% | Large |
| NTechLAB - facenx_small | 10/20/2015 | 66.366% | 66.427% | 66.427% | Small |
| Beijing Faceall Co. - FaceAll_1600 | 10/19/2015 | 63.96% | 64.983% | 63.96% | Large |
| Barebones_FR - cnn | 10/21/2015 | 59.036% | 59.036% | 59.036% | Small |
| 3DiVi Company - tdvm6 | 10/27/2015 | 36.927% | 37.967% | 36.927% | Small |
| Joint Bayes | 10/20/2015 | 2.173% | 2.204% | 2.204% | Small |
| LBP | 10/20/2015 | 1.465% | 1.465% | 1.465% | Small |
| EM-DATA | 6/14/2018 | 0.982029% | 0.982029% | 0.982029% | Large |
Method Details
| Algorithm | Details |
|---|
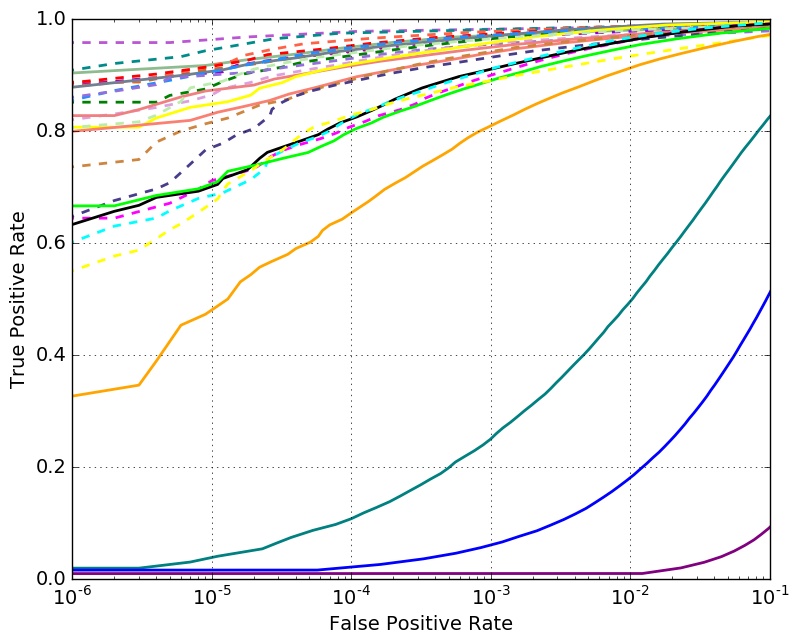
Verification Performance with 1 Million Distractors
Verifification Performance with 10K Distractors
- - uses large training set
Set 1
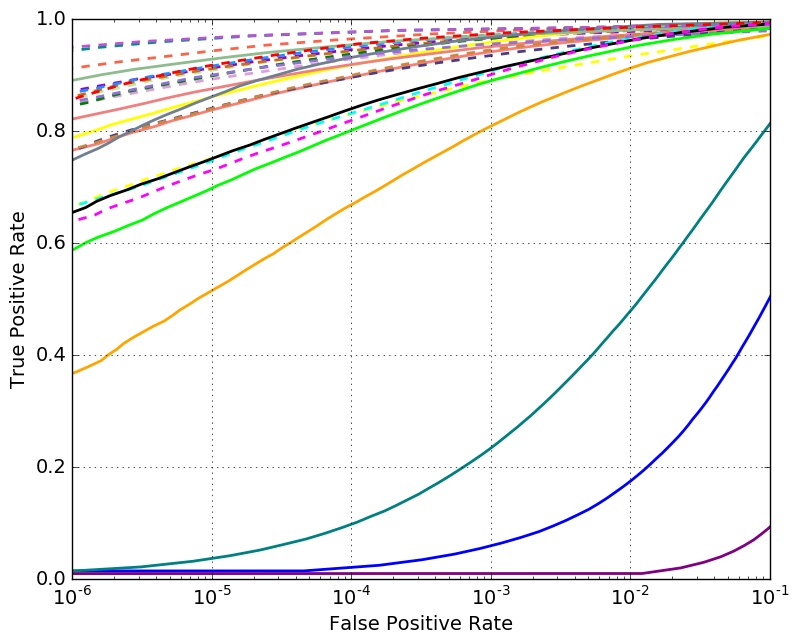
Set 1
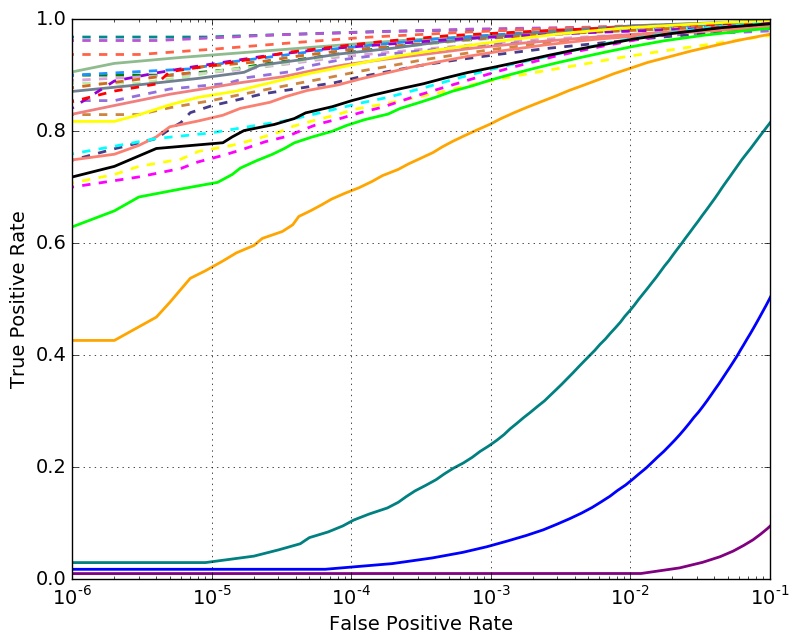
- - uses large training set
Set 2
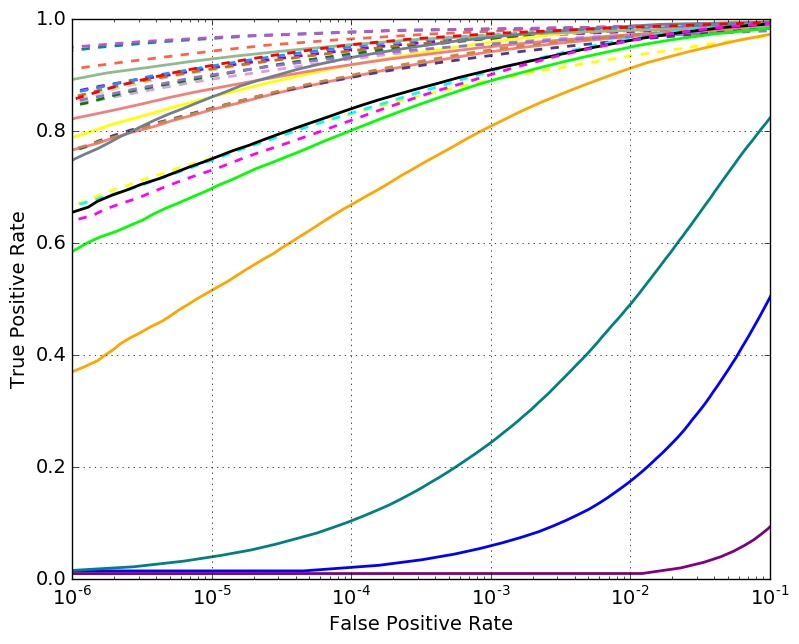
Set 2
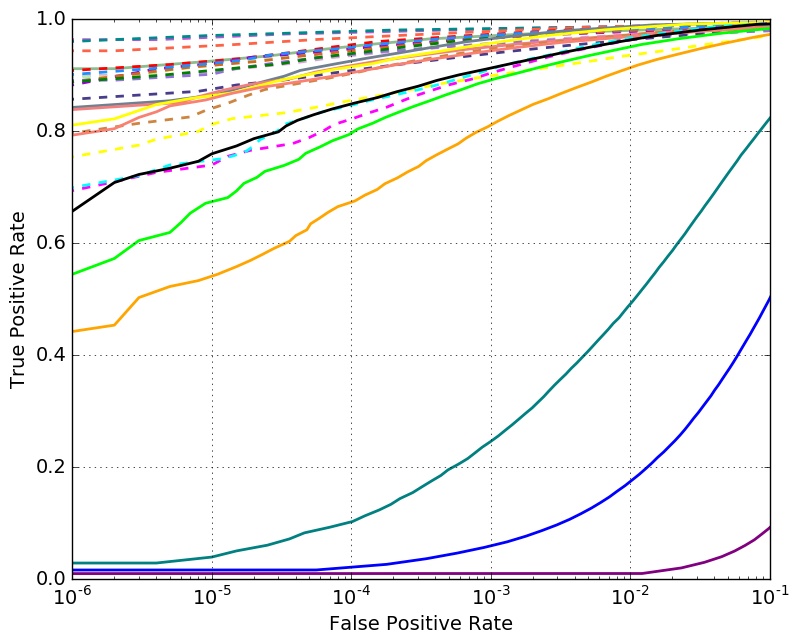
- - uses large training set
Set 3
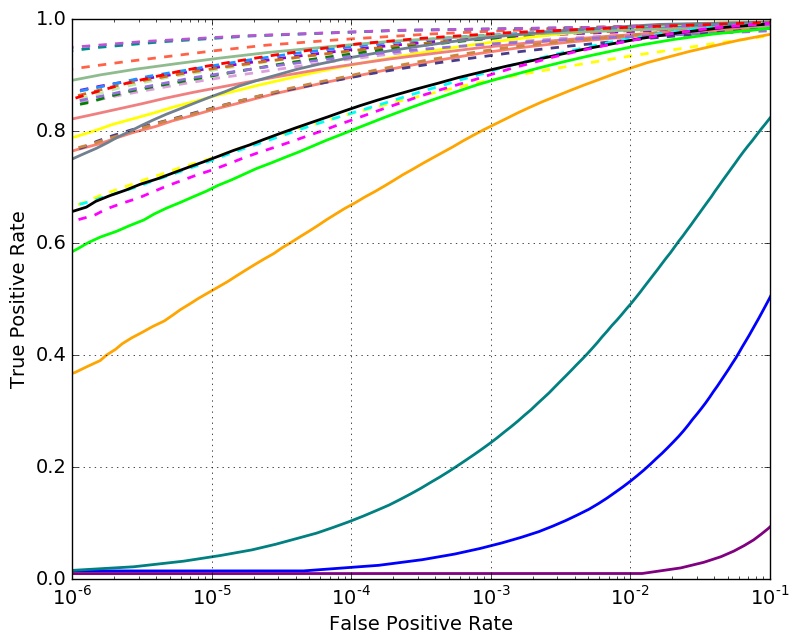
Set 3
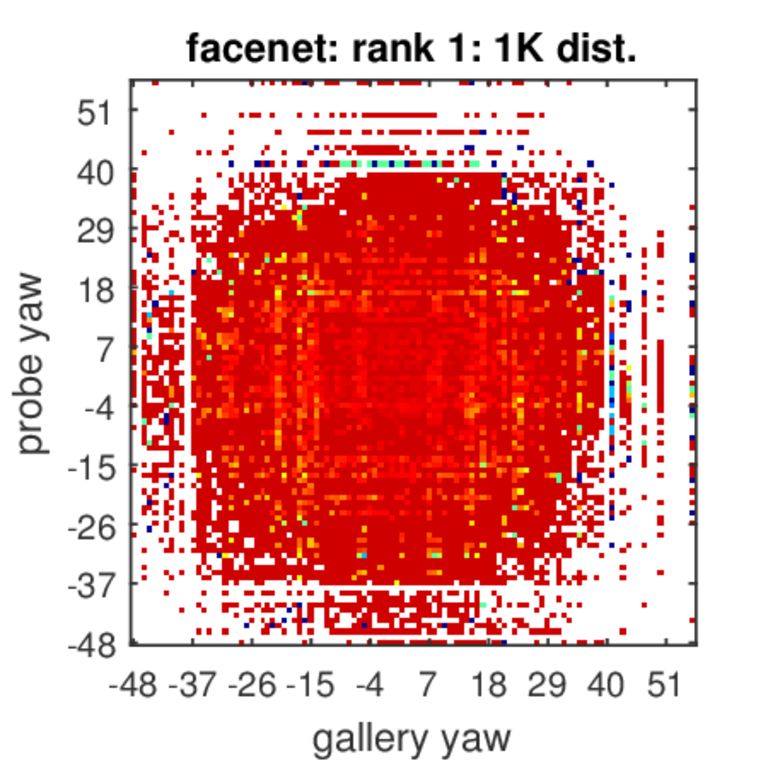
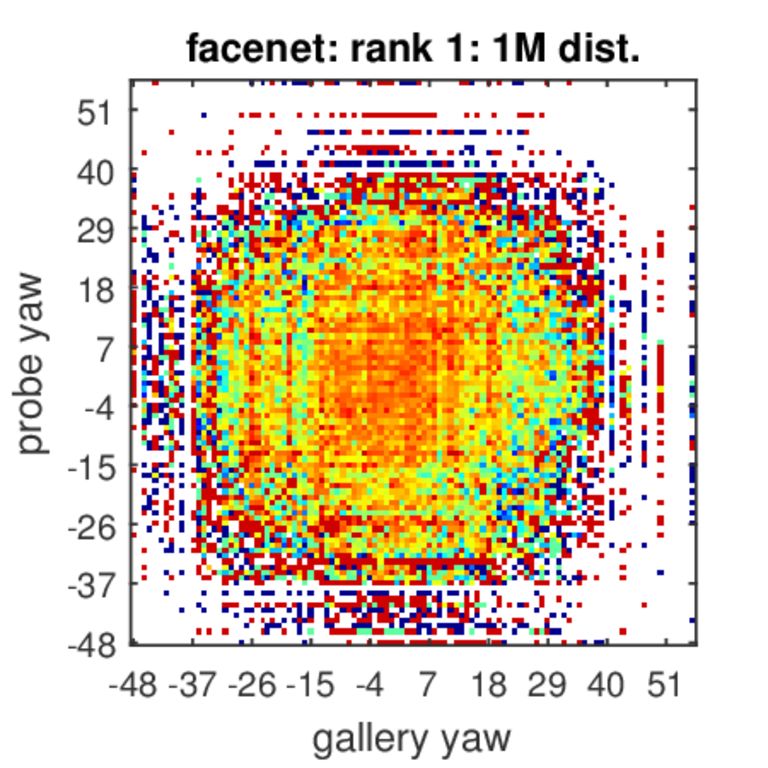
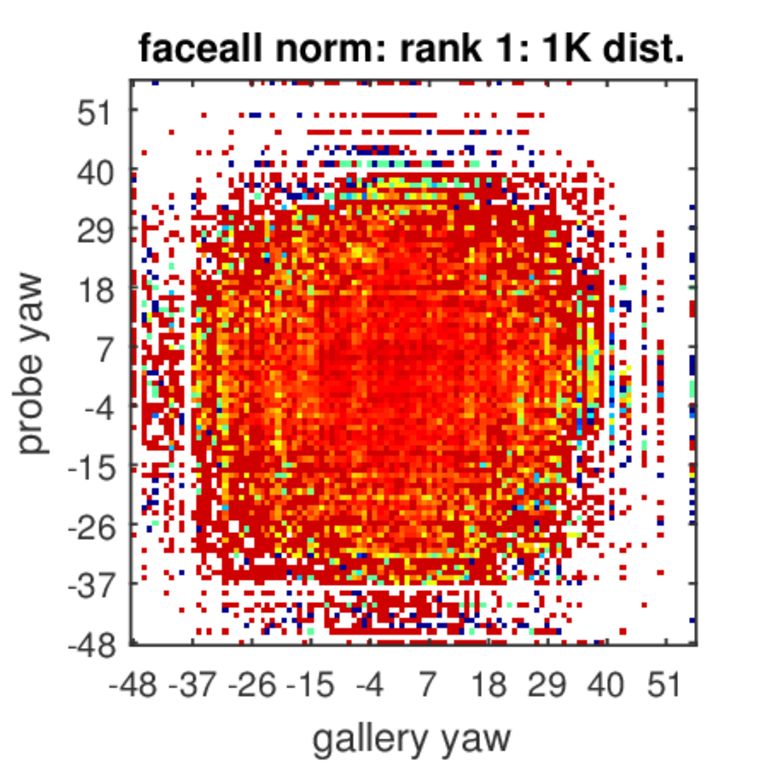
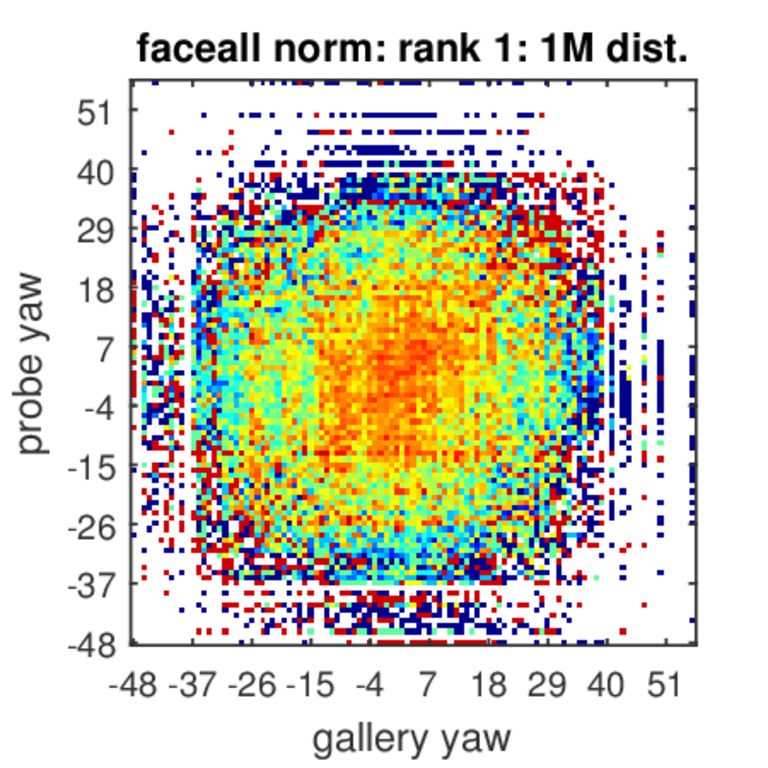
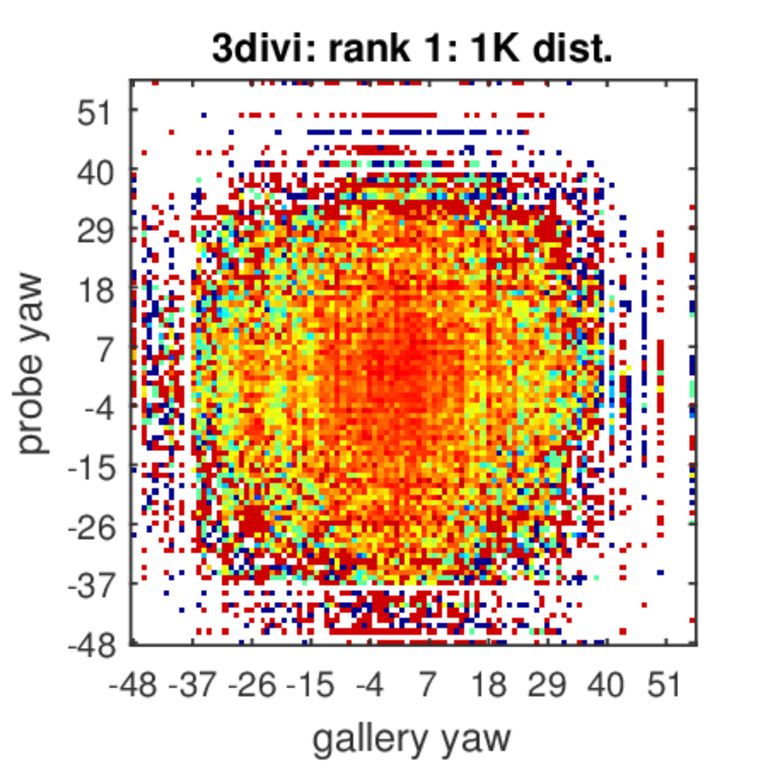
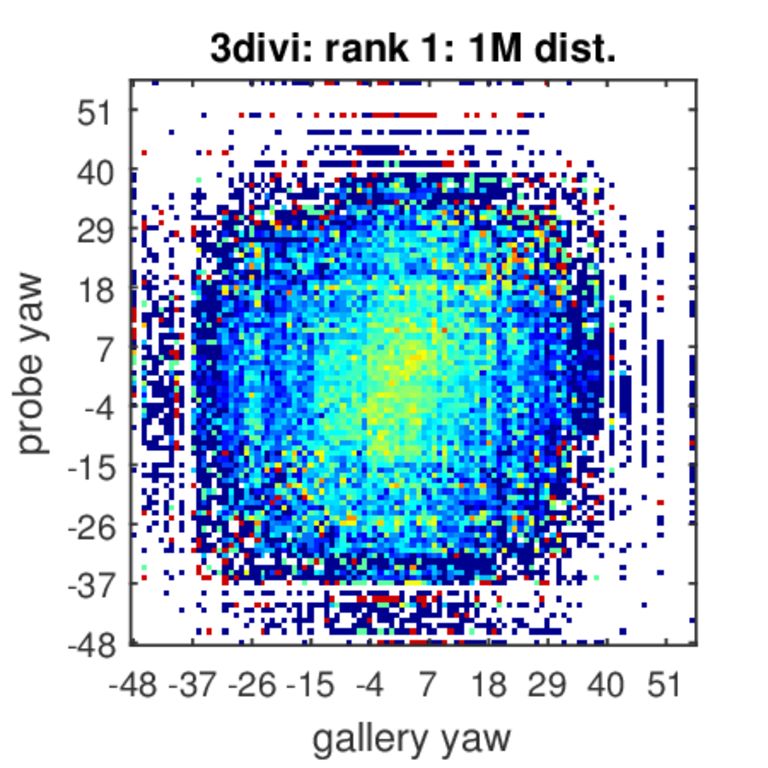
Analysis of Rank-1 Identification for Varying Poses
The colors represent identification accuracy going from 0(=blue)–none of the true pairs were matched to 1(=red)–all possible combinations of probe and gallery were matched per probe and gallery ages. White color indicates combinations of poses that did not exist in our test set.